Real-time Data Aggregation with
Jeremy Mikola
@jmikola
Agenda

- Available Tools
- Schemas
- Commands
- MapReduce
- Aggregation Framework
- Pipeline, Expressions
- Usage, Sharding
- Looking Ahead
Setting the Stage
We have data stored in MongoDB.
We need to do ad-hoc reporting,
grouping, common aggregations, etc.
What can we use for this?
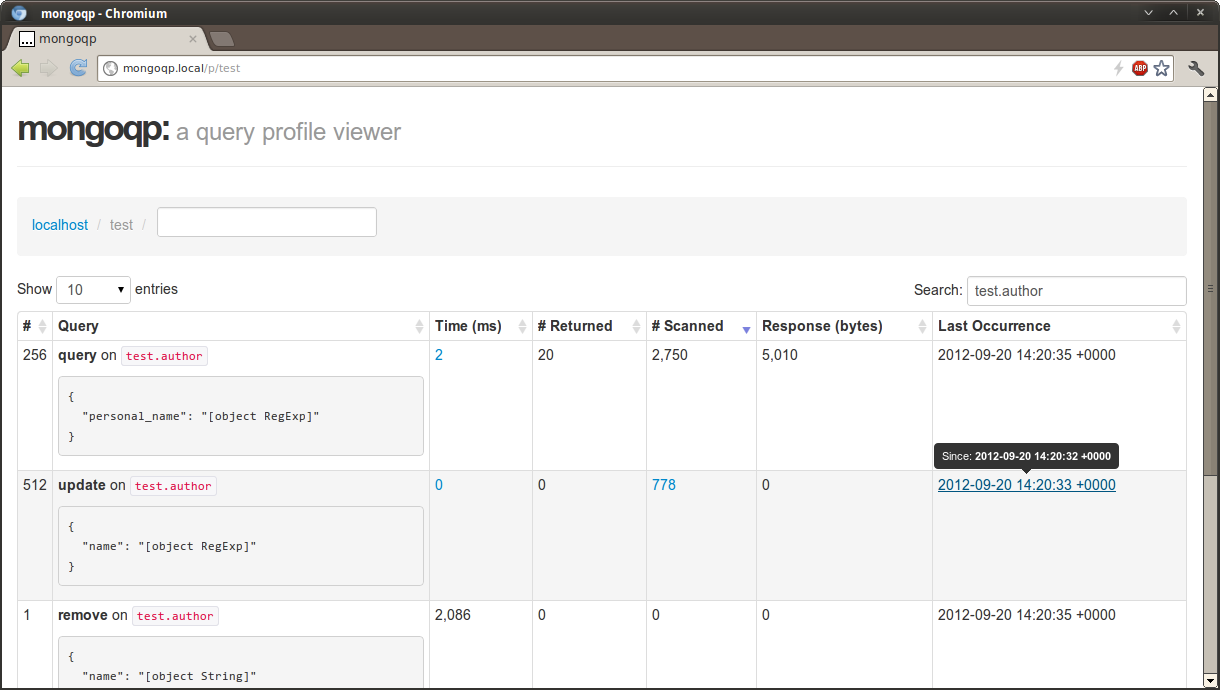
And now for something completely different…

Pipeline
Pipeline Operators
$match$project$group$unwind
$sort$limit$skip$geoNear
$match
Matching field values
{ title: "The Great Gatsby",
pages: 218,
language: "English"
}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
►
{ $match: {
language: "Russian"
}}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}$match
Matching with query operators
{ title: "The Great Gatsby",
pages: 218,
language: "English"
}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
►
{ $match: {
pages: { $gt: 1000 }
}}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}$project
Including and excluding fields
{ _id: 375,
title: "The Great Gatsby",
ISBN: "9781857150193",
available: true,
pages: 218,
chapters: 9,
subjects: [
"Long Island",
"New York",
"1920s"
],
language: "English"
}
►
{ $project: {
_id: 0,
title: 1,
language: 1
}}{ title: "The Great Gatsby",
language: "English"
}$project
Renaming and computing fields
{ _id: 375,
title: "The Great Gatsby",
ISBN: "9781857150193",
available: true,
pages: 218,
chapters: 9,
subjects: [
"Long Island",
"New York",
"1920s"
],
language: "English"
}
►
{ $project: {
avgPagesPerChapter: {
$divide: [
"$pages",
"$chapters"
]
},
lang: "$language"
}}{ _id: 375,
avgPagesPerChapter: 24.2222222222,
lang: "English"
}$project
Creating and extracting sub-document fields
{ _id: 375,
title: "The Great Gatsby",
ISBN: "9781857150193",
available: true,
pages: 218,
chapters: 9,
subjects: [
"Long Island",
"New York",
"1920s"
],
publisher: {
city: "London",
name: "Random House"
}
}
►
{ $project: {
title: 1,
stats: {
pages: "$pages",
chapters: "$chapters",
},
pub_city: "$publisher.city"
}}{ _id: 375,
title: "The Great Gatsby",
stats: {
pages: 218,
language: "English"
},
pub_city: "London"
}$group
Calculating an average
{ title: "The Great Gatsby",
pages: 218,
language: "English"
}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
►
{ $group: {
_id: "$language",
avgPages: { $avg: "$pages" }
}}{ _id: "Russian",
avgPages: 1440
}{ _id: "English",
avgPages: 653
}$group
Summating fields and counting
{ title: "The Great Gatsby",
pages: 218,
language: "English"
}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
►
{ $group: {
_id: "$language",
numTitles: { $sum: 1 },
sumPages: { $sum: "$pages" }
}}{ _id: "Russian",
numTitles: 1,
sumPages: 1440
}{ _id: "English",
numTitles: 2,
sumPages: 1306
}$group
Collecting distinct values
{ title: "The Great Gatsby",
pages: 218,
language: "English"
}{ title: "War and Peace",
pages: 1440,
language: "Russian"
}{ title: "Atlas Shrugged",
pages: 1088,
language: "English"
}
►
{ $group: {
_id: "$language",
titles: { $addToSet: "$title" }
}}{ _id: "Russian",
titles: [ "War and Peace" ]
}{ _id: "English",
titles: [
"Atlas Shrugged",
"The Great Gatsby"
]
}$unwind
Yielding multiple documents from one
{ _id: 375,
title: "The Great Gatsby",
subjects: [
"Long Island",
"New York",
"1920s"
]
}
►
{ $unwind: "$subjects" }{ _id: 375,
title: "The Great Gatsby",
subjects: "Long Island"
}{ _id: 375,
title: "The Great Gatsby",
subjects: "New York"
}{ _id: 375,
title: "The Great Gatsby",
subjects: "1920s"
}$sort
Sort all documents in the pipeline
{ title: "The Great Gatsby" }{ title: "Brave New World" }{ title: "The Grapes of Wrath" }{ title: "Animal Farm" }{ title: "Lord of the Flies" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }{ title: "Fahrenheit 451" }
►
{ $sort: { title: 1 }}{ title: "Animal Farm" }{ title: "Brave New World" }{ title: "Fahrenheit 451" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }{ title: "Lord of the Flies" }{ title: "The Grapes of Wrath" }{ title: "The Great Gatsby" }$limit
Limit documents through the pipeline
{ title: "Animal Farm" }{ title: "Brave New World" }{ title: "Fahrenheit 451" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }{ title: "Lord of the Flies" }{ title: "The Grapes of Wrath" }{ title: "The Great Gatsby" }
►
{ $limit: 5 }{ title: "Animal Farm" }{ title: "Brave New World" }{ title: "Fahrenheit 451" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }$skip
Skip over documents in the pipeline
{ title: "Animal Farm" }{ title: "Brave New World" }{ title: "Fahrenheit 451" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }
►
{ $skip: 2 }{ title: "Fahrenheit 451" }{ title: "Fathers and Sons" }{ title: "Invisible Man" }Expressions
Usage
Sharding
Sharding
shard1
↘
$match$group1
shard2
↓
$match$group1
shard3
mongos
↓
$group2$sort$project
Result